Buffer Overflow & gdb – Part 1
0x0ff.info est de nouveau sur les rails, histoire de marquer le coup j’ai choisi de traiter un épineux sujet (c’est noël après tout) et terrifiant sujet, l’utilisation du débogueur gdb !.. Cependant n’oublions pas, nous somme sur un vil site de vilains hackers, cette étude se fera autour d’un programme vulnérable au Buffer Overflow, une faille système de grande renommée, nécessitant pour l’exploiter, du tact et des doigts de fée.
Se former au débogueur, ou même à l’exploitation des différents failles de dépassement de tampon n’est pas chose aisée. Et pour découvrir seul cet univers il faut s’armer de patience, de courage, et d’une boîte d’antimigraineux… Mais rassurez-vous je suis passé devant pour défricher un peu la voie.
Ce cours se présentera sous forme d’une série d’articles, oui vous avez bien entendu, Série. A l’heure ou j’écris cette introduction, au moins deux autres articles sont en phase de relecture, et encore deux sont en phase de draft. Cet étalement permettra d’apporter une pincée d’explications par-ci, et une cuillerée de détails par là, bref de surmonter ce petit quelque chose qui a peut-être coincé chez ceux ayant déjà voulu se lancer une première fois.
Néophyte ou initié, j’espère que vous serez séduit par cette entrée en matière…
Note : Tous les liens placés sur des mots clés redirigent vers des pages pertinentes, souvent Wikipedia. Je vous invite à les suivre, ce ne sont pas des liens commerciaux !
Un débogueur c’est quoi ?
Un débogueur est un outil permettant de déboguer un programme. Ce truisme énoncé voici quelques explications. Si il est possible de déboguer avec un débogueur c’est qu’il est capable de récupérer un certain nombre d’informations sur l’exécution d’un programme qui sont normalement inaccessible à l’utilisateur car trop bas niveau. Il existe de nombreux outils qui permettent de déboguer un programme : ptrace, ltrace, dmesg… Mais généralement lorsque l’on parle de débogueur, on parle de Ollydbg ou ida sous Windows, et gdb sous Linux.
Dans un premier temps nous allons nous intéresser uniquement à gdb qui permet de désassembler dynamiquement un programme au format ELF (Executable and Linkable Format). Le désassemblage est la traduction du code binaire en instructions du langage assembleur (asm). gdb à l’instar d’Ollydbg effectue ce travail à la volée lors de l’exécution du programme. A contrario, Ida permet de désassembler le fichier du programme sans avoir besoin de l’exécuter en reconnaissant certains patterns (groupes d’octets) et en les identifiant comme correspondant à certaines instructions.
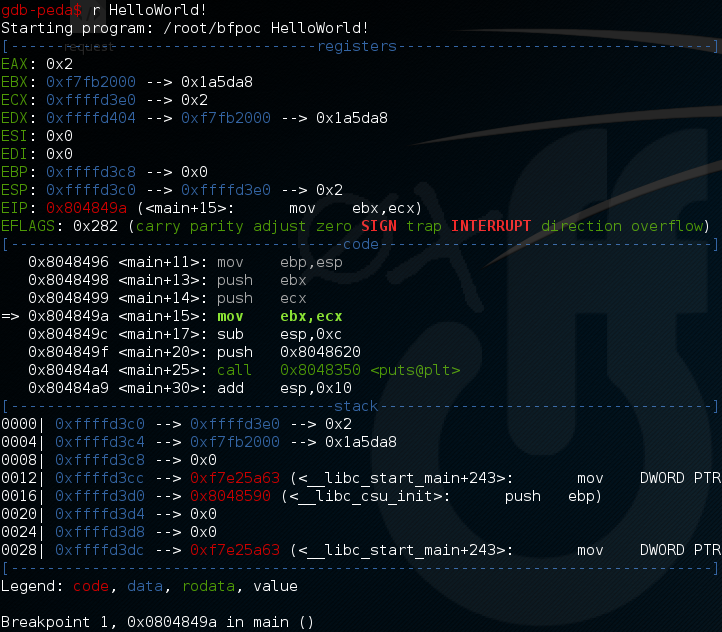
Ci-dessus l’interface en ligne de commande de gdb avec la surcouche peda. Vous frôlez l’indigestion ? Ne vous inquiétez pas, on apprend à aimer, et au bout d’un moment ça devient comme une seconde nature. Repensez à cette scène de Matrix ou Cypher regarde la Matrice défiler en parlant à Néo, et dites vous que c’est pareil.
On finit par s’y habituer, et en fait, je vois même plus le code : tout ce que je vois, c’est des blondes, des brunes, des rousses…
Comme tous les débogueur gdb, permet de faire un certain nombre de manipulations sur un programme que nous etudierons un peu plus tard… Pour vous donner un rapide aperçu des possibilités qu’offre gdb, sachez que sa fonction principale est de fournir une représentation de la mémoire au cours de l’exécution d’un programme. Peu utile vu la vitesse à laquelle se déroule l’exécution du dit programme me direz-vous ?
Oui, mais gdb permet également de mettre le programme en pause en cours d’exécution ! On appelle ça un breakpoint et dans gdb, c’est votre meilleur ami . Il est possible de définir plusieurs pauses et de naviguer entre ces interruptions. Lorsque le programme est arrêté à un breakpoint, une représentation de la mémoire est affichée et d’autres informations sont disponibles au travers certaines commandes.
Il est aussi possible d’exécuter le programme instruction par instruction, c’est ce que l’on appelle un step. Et quand je parle d’instruction, je parle d’instruction en langage assembleur (voir image ci-dessus bloc “code”). Pour rappel, le langage ASM est le langage le plus bas niveau encore intelligible avant les signaux constitués de 0 et de 1…
La mémoire
Ne nous emballons pas, avant de se lancer dans le vif du sujet, je pense qu’il est judicieux de faire un petit rappel sur la mémoire et les processus. Mais ne vous inquiétez pas je ne vais pas entrer dans les détails, seulement vous brosser un rapide tableau de comment fonctionne tout ça en me concentrant sur ce qui est vraiment pertinent pour exploiter un buffer overflow avec gdb.
Lorsque vous exécutez un programme, votre processeur va effectuer un certain nombre de calculs correspondant aux différentes lignes de code de ce programme. Pour effectuer ces calculs rapidement, il a besoin de stocker certaines données là où elles seront très vite accessibles, deux solutions s’offrent à lui :
- Les registres processeurs : sur x86 on peut citer EAX/EBX/EIP/ESP/EBP… Bref ce sont de petits espaces mémoires contenus à l’intérieur même du processeur et utilisés pour diverses choses. Vous trouverez le détail de ces registres dans la Cheat Sheet ci-dessous.
- La mémoire vive : C’est dans vos barrettes de RAM que sont stockées la majorité des informations nécessaires à l’exécution de vos programmes : les variables, les pointeurs, la pile (ou stack), le tas (ou heap), etc…
L’espace mémoire disponible dans la RAM est assez conséquent. Afin de retrouver rapidement l’information les octets sont numérotés, on parle alors d’adresses. Par exemple, à l’adresse 0xbfffaabb on retrouve le 3221203643ième octet de la mémoire vive.
![]() Pour ouvrir une petite parenthèse c’est exactement à cause de ce système d’adressage que les systèmes 64bit permettent d’ajouter plus de RAM à votre ordinateur que les systèmes 32bit. En effet 32 ou 64 bit fait référence à la longueur du bus d’adresse (la partie d’un processeur en charge de l’adressage), un système 32bit permet des adresses longues de 2^32 bits soit 4 octets (de 0x0 à 0xffffffff) et donc 4294967296 adresses différentes. La première partie de ces adresses est réservée à certaines ressources (carte mère, carte graphique, etc…) ce qui ne laisse à la disposition des programmes qu’environ 3Go de RAM. Je vous laisse suivre cette même logique pour trouver la limite d’un système 64bit. :p
Pour ouvrir une petite parenthèse c’est exactement à cause de ce système d’adressage que les systèmes 64bit permettent d’ajouter plus de RAM à votre ordinateur que les systèmes 32bit. En effet 32 ou 64 bit fait référence à la longueur du bus d’adresse (la partie d’un processeur en charge de l’adressage), un système 32bit permet des adresses longues de 2^32 bits soit 4 octets (de 0x0 à 0xffffffff) et donc 4294967296 adresses différentes. La première partie de ces adresses est réservée à certaines ressources (carte mère, carte graphique, etc…) ce qui ne laisse à la disposition des programmes qu’environ 3Go de RAM. Je vous laisse suivre cette même logique pour trouver la limite d’un système 64bit. :p
Si vous vous référez à l’infographie que j’ai produite il y a de ça quelques temps et que vous pouvez retrouver ci-dessous, vous constaterez qu’a l’initialisation d’un programme, un certain nombre d’espaces mémoires qui lui sont propres sont définis texte, GVar, BSS, Heap, Stack… Pour le moment nous allons nous intéresser exclusivement à la Stack qui est un espace mémoire ou les buffer overflows sont communs.
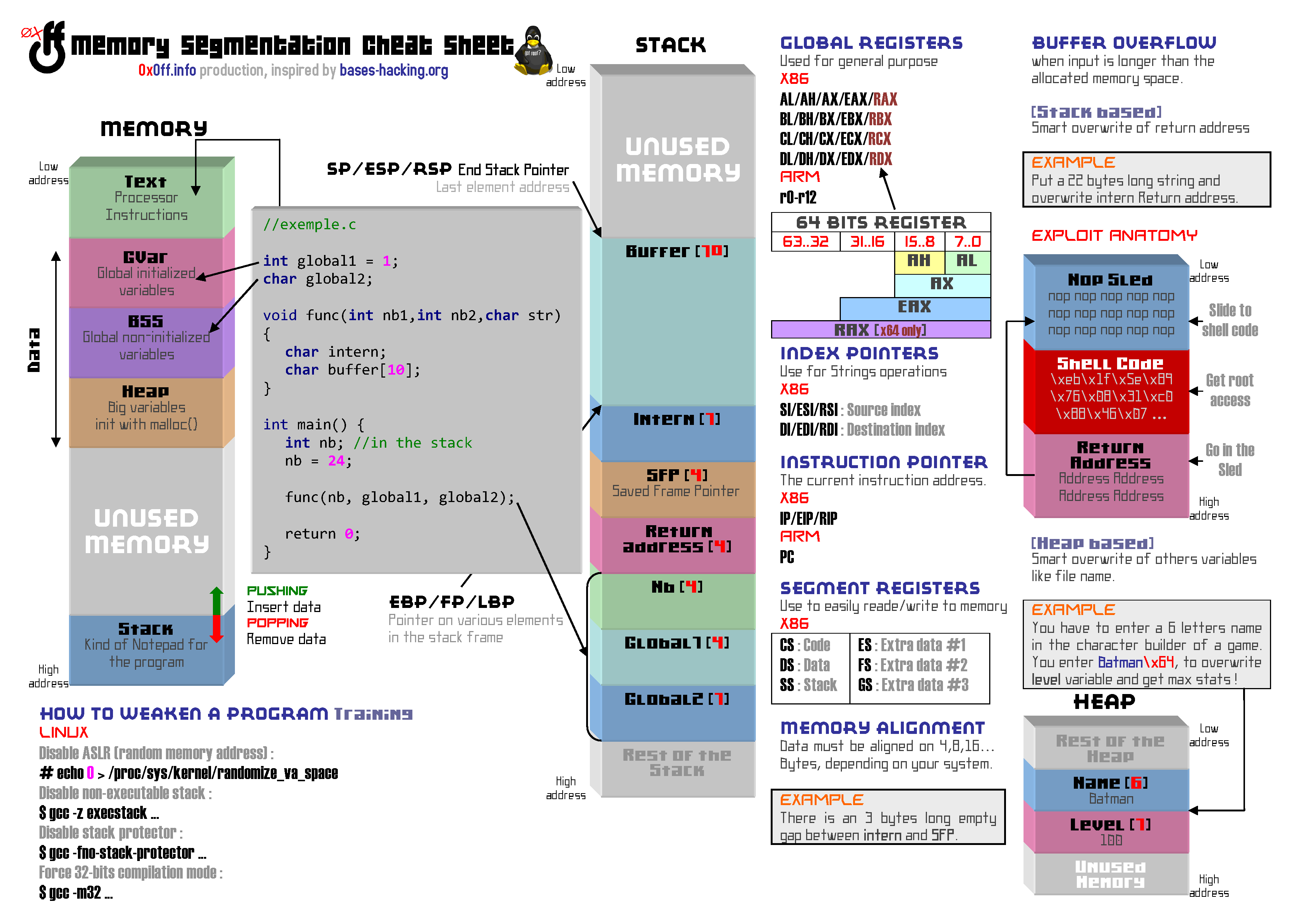
Pile ou Stack
Il faut imaginer la stack comme une sorte de bloc-note adapté à votre machine. Cet espace mémoire fait un peu office de fourre tout, et contient presque toutes les variables et pointeurs utilisés par les différentes fonctions de vos programmes. Chaque fonction possède sa propre portion de stack, appelée stack frame…
L’une des particularités de la stack est qu’elle croît vers les adresses basses. C’est à dire qu’en déclarant successivement deux variables a et b :
char a; char b;
La variable a aura une adresse plus grande que la variable b. Par exemple 0xbfffa2 pour a et 0xbfffa1 pour b… Je sais je sais, ce n’est pas facile à appréhender mais il va falloir vous y habituer. D’autant que ce n’est pas le plus dur à assimiler…
Et oui, une autre particularité joyeuse de la mémoire sous Linux est la représentation Little Endian. Comme vous le savez certainement, la place prise par les données en mémoire peut varier (si vous l’ignoriez je vous conseille de jeter un œil à ce papier : Sales types de données !). Le format Little Endian ou Big Endian influe sur la façon dont les données sont ordonnées. Imaginons un pointeur pointant sur une chaîne de caractères. Ce pointeur, comme tous les pointeurs d’un système 32bit est long de 4 octets (ce qui correspond à la taille d’une adresse vous vous souvenez ?). Imaginons que ce pointeur soit situé à l’adresse 0xbfffaa00 et contienne l’adresse du premier caractère de notre string 0xbfffbbcc, voici comment il serait représenté en fonction de l’endianness.

Big Endian
0xBFFFAA00 : 0xBF 0xBFFFAA01 : 0xFF 0xBFFFAA02 : 0xBB 0xBFFFAA03 : 0xCC |
Little Endian
0xBFFFAA00 : 0xCC 0xBFFFAA01 : 0xBB 0xBFFFAA02 : 0xFF 0xBFFFAA03 : 0xBF |
Mise en place
Installation de peda pour gdb
Comme tout programme fameux, gdb rassemble une communauté de gens malins. Et comme bien souvent cette communauté est à l’origine d’améliorations géniales. L’une d’entre elles se nomme PEDA pour Python Exploit Development Assistance for GDB : https://github.com/longld/peda.
Cette surcouche ajoute un peu de couleur à la masse d’informations fournie par gdb, ce qui n’est pas du luxe ! Voici comment procéder pour l’installer :
git clone https://github.com/longld/peda.git ~/peda echo "source ~/peda/peda.py" >> ~/.gdbinit echo "DONE! debug your program with gdb and enjoy"
Ecrire un programme vulnérable au buffer-overflow
Première étape pour notre étude de gdb, écrire un programme vulnérable au buffer overflow car nous sommes sur un blog d’InfoSec vingt dieux !
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void funcMyLife();
main(int argc, char **argv)
{
printf("[0] main() Start here.\n");
if(argc != 2)
{
printf("[X] Usage : %s <message>\n", argv[0]);
exit(0);
}
printf("[1] Calling funcMyLife().\n");
funcMyLife(argv[1]);
printf("[6] main() end at the next instruction. \n");
return 0;
}
void funcMyLife(const char *arg)
{
printf("[2] funcMyLife() Start here.\n");
printf("[3] Variable buffer declaration.\n");
char buffer[128];
printf("[4] Calling strcpy(). <= [Vulnerability]\n");
strcpy(buffer, arg);
printf("\nMessage : %s\n\n", buffer);
printf("[5] funcMyLife() end at the next instruction (ret).\n");
}
Compiler notre programme en limitant les protections
Malheureusement pour vous jeunes hackers, l’informatique évolue plutôt rapidement, et au fil des années de nombreuses sécurités ont été développées afin de rendre l’exploitation de ces vulnérabilités un véritable calvaire :
- La protection ASLR (Address Space Layout Randomization) permet de rendre l’anatomie des processus aléatoire. A chaque nouvelle exécution, les données stockées sont placées à des endroits différents de la mémoire.
- La protection SSP (Stack-Smashing Protector) intercale des espaces mémoire entre les données utiles de la stack. L’intégrité de ces espaces est contrôlée. Toute modification de ces “Canary” cause l’interruption du programme.
- Pas d’exécution possible dans la Stack et le Heap, ces espaces mémoire sont destinés à contenir des variables et des pointers mais en aucun cas du code exécutable.
Afin de simplifier au maximum cette introduction, nous allons désactiver toutes ces protections. Nous allons aussi forcer la compilation en 32bit (pour ceux comme moi qui utilisent un système 64bit) :
# Cette étape peut s'avérer nécessaire si votre système est en 64bit et que vous ne disposez pas des librairies permettant de compiler en 32bit apt-get install libc6-dev-i386 # Désactiver l'ASLR echo 0 > /proc/sys/kernel/randomize_va_space # Compilation 32bit, stack exécutable, pas de stack protector gcc -m32 -g -z execstack -fno-stack-protector ./bfpoc.c -o bfpoc
Mise en évidence du buffer overflow
Maintenant que nous avons fabriqué notre binaire vulnérable, il ne nous reste plus qu’à mettre en évidence le buffer overflow. Si vous avez fait l’effort de lire le code, vous devez maintenant savoir que le programme prend la chaîne de caractères passée en paramètre et la copie dans la variable buffer[128] un espace mémoire qui peut théoriquement contenir 127 caractères ainsi que le caractère de fin de chaîne 0x00.
Mais voyons tout d’abord comment ce programme se comporte hors gdb et sans aucun outil de débogage… Car oui, bien étudier le comportement d’un programme fait gagner du temps, c’est donc un réflexe à adopter dés maintenant.
Fonctionnement normal
./bfpoc aaa
[0] main() Start here.
[1] Calling funcMyLife().
[2] funcMyLife() Start here.
[3] Variable buffer declaration.
[4] Calling strcpy(). <= [Vulnerability]
Message : aaa
[5] funcMyLife() end at the next instruction (ret).
[6] main() end at the next instruction.
Dépassement de mémoire de 1 octet
./bfpoc $(python -c 'print "a"*128') [0] main() Start here. [1] Calling funcMyLife(). [2] funcMyLife() Start here. [3] Variable buffer declaration. [4] Calling strcpy(). <= [Vulnerability] Message : aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa [5] funcMyLife() end at the next instruction (ret). [6] main() end at the next instruction.
En effet, les données situées juste après l’espace réservé à la variable buffer[128] on peut-être déjà été utilisées, ou ne sont pas essentielles, ou peut-être que l’octet écrasé contenait déjà la valeur 0x00. Sans oublier le concept d’alignement mémoire qui peut causer des gap de mémoire inutilisée (Voir le paragraphe Alignement Mémoire de l’article Sales types de données)…
En passant en paramètre une chaîne de 128 caractères, 129 caractères sont copiés dans la variable buffer[128] à cause du caractère de fin de chaîne 0x00 automatiquement ajouté. Pourtant ce dépassement de mémoire ne génère pas d’erreur… Étrange ? Pas forcément…
Segmentation Fault #1
./bfpoc $(python -c 'print "a"*136') [0] main() Start here. [1] Calling funcMyLife(). [2] funcMyLife() Start here. [3] Variable buffer declaration. [4] Calling strcpy(). <= [Vulnerability] Message : aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa [5] funcMyLife() end at the next instruction (ret). [6] main() end at the next instruction. Erreur de segmentation
En augmentant le nombre de caractères de notre chaîne passée en argument, on finit par obtenir ce que l’on cherche : une erreur Segmentation Fault significative du buffer overflow. Pourtant il ne s’agit pas de celui que l’on cherche car l’erreur se produit seulement à la sortie de la fonction main…
Segmentation Fault #2
./bfpoc $(python -c 'print "a"*140') [0] main() Start here. [1] Calling funcMyLife(). [2] funcMyLife() Start here. [3] Variable buffer declaration. [4] Calling strcpy(). <= [Vulnerability] Message : aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa [5] funcMyLife() end at the next instruction (ret). Erreur de segmentation
Il suffit de pousser le bouchon un peu plus loin pour finalement trouver ce que l’on cherche, une erreur de segmentation empêchant de sortir de la fonction funcMyLife(). C’est très intéressant pour nous, car cela veut dire que la Return Address de la fonction a été écrasée par ce que l’on a saisi.
La Return Address est un pointeur qui est positionné en début de stack, à l’entrée dans la fonction, et qui a pour mission de sauvegarder l’emplacement de la prochaine instruction à exécuter à la sortie de la fonction.
Conclusion de la partie 1
Et voilà ! Cette première partie se termine ici et je sens que vous bouillonnez “Pfff! On a même pas lancé gdb, quelle arnaque !“. Oui bon, mais avouez que ce n’était pas si inintéressant tout compte fait… Ce qui est certain c’est qu’il était important de voir ou revoir les bases avant de se lancer dans l’aventure. Les débogueurs, les buffer overflows, tout ça sont des sujets relativement compliqués et il est primordial de savoir exactement ce que l’on fait et pourquoi on le fait. Considérez que l’on vient de poser les fondations. On s’attaquera aux gros oeuvre dans la partie 2, et je vous rassure dés à présent, on utilisera bien gdb.








