Sales types de données !
 Je suis régulièrement confronté à des personnes, parfois même des professionnels de l’informatique qui font la confusion entre ce qui est affiché à l’écran et ce qui est compris par le programme. Cette erreur fréquente est sans doute le symptôme d’une méconnaissance des différents types de données que l’on peut rencontrer et qui peuvent varier en fonction du langage de programmation.
Je suis régulièrement confronté à des personnes, parfois même des professionnels de l’informatique qui font la confusion entre ce qui est affiché à l’écran et ce qui est compris par le programme. Cette erreur fréquente est sans doute le symptôme d’une méconnaissance des différents types de données que l’on peut rencontrer et qui peuvent varier en fonction du langage de programmation.
Je vais essayer de débrouiller tous les nœuds qu’il existe sous nombre de crânes entres toutes ces notions simples qui ont été amassées au court du temps sans que personne ne prennent le temps de les ranger soigneusement. Le sujet du jour portera sur les différentes formes que peut prendre une même unité d’information… Disons, le nombre 67, aussi banal qu’il puisse paraître.. Lorsqu’il est utilisé dans un langage tout aussi banal, le langage C.
D’ailleurs avant toute chose je tiens à lever une autre ambiguïté terriblement agaçante qui finalement est intrinsèquement liée à ce que je m’apprête à vous expliquer. Nous avons tous été confronté à un moment ou à un autre à cette situation un peu casse couille où quelqu’un vous reprend lorsque vous avez le malheur de dire un truc du style “nombre 7” au lieu de “chiffre 7”. Or le mot “chiffre” désigne le type de symboles qui compose les “nombres” de la même manière que le mot “lettre” désigne le type de symboles qui compose les “mots”. Et si un mot d’une lettre existe, un nombre d’un chiffre existe tout autant. – True story
La base…
Prenons donc le nombre 88 pour… Quoi ? J’avais dit 67 ? Et alors, j’ai changé d’avis, vous allez pas en chier une pendule si ?! Donc, je disais, prenons le nombre 111 car il mérite toute notre attention. En effet ce nombre a la particularité d’exister dans toutes les bases. Sa valeur bien entendu, mais également sa représentation (trois chiffres 1 consécutif).
Il est évident qu’une représentation identique pour des valeurs différentes pose problème. Voilà pourquoi il est coutume de préfixer le nombre lorsqu’il n’appartient pas au système décimal… Seulement ce n’est pas toujours le cas, et ce qui est affiché peut être mal interprété par l’utilisateur.
111 (décimal)
| Décimal | Hexadécimal | Binaire |
| 111 | 6F | 110 1111 |
0x111 (hexadécimal)
| Décimal | Hexadécimal | Binaire |
| 273 | 111 | 0001 0001 0001 |
0b111 (binaire)
| Décimal | Hexadécimal | Binaire |
| 7 | 07 | 000 0111 |
Voici un petit programme qui vous permettra de vérifier tout ça, incrédules que vous êtes :
#include <stdio.h> main() { int nombre1=111; int nombre2=0x111; int nombre3=0b111; // En décimal printf("%d\n",nombre1); printf("%d\n",nombre2); printf("%d\n",nombre3); // En hexadécimal printf("%x\n",nombre1); printf("%x\n",nombre2); printf("%x\n",nombre3); }
Ces quelques lignes de codes illustrent parfaitement l’une des problématiques inhérente aux langages de programmations. Une valeur, bien qu’initiée d’une certaine façon, peut être utilisée d’une autre manière… Dans cet exemple, bien que les trois variables soient initialisées différemment : en décimal, en hexadécimal puis en binaire. Pour afficher leur contenu à l’écran, il est nécessaire de préciser le format de sortie… Il convient donc d’avoir une idée très précise de ce que l’on souhaite faire et de ce qui se passe derrière les lignes de code pour ne pas tomber dans ces ornières déjà pleines d’imprudents.
Espace mémoire
Ce fameux nombre 111 peut donc être stocké en utilisant un seul et unique octet… Notez que je n’ai pas dit qu’il doit ou va être stocké en utilisant un seul octet !
Dans la plupart des langages de programmation, l’espace utilisé est défini par le type de la variable que l’on utilise pour stocker cette information.
Prenons le tableau proposé par le premier site que l’on trouve sur internet en cherchant “C Data Types” qui présente assez bien les choses sur l’allocation mémoire propre aux différents types de données :
| Type de donnée | Signification | Taille (en octets) | Plage de valeurs acceptée |
|---|---|---|---|
| char | Caractère | 1 | -128 à 127 |
| unsigned char | Caractère non signé | 1 | 0 à 255 |
| short int | Entier court | 2 | -32 768 à 32 767 |
| unsigned short int | Entier court non signé | 2 | 0 à 65 535 |
| int | Entier | 2 4 |
-32 768 à 32 767 -2 147 483 648 à 2 147 483 647 |
| unsigned int | Entier non signé | 2 4 |
0 à 65 535 0 à 4 294 967 295 |
| long int | Entier long | 4 | -2 147 483 648 à 2 147 483 647 |
| unsigned long int | Entier long non signé | 4 | 0 à 4 294 967 295 |
| float | Flottant (réel) | 4 | 3.4*10-38 à 3.4*1038 |
| double | Flottant double | 8 | 1.7*10-308 à 1.7*10308 |
| long double | Flottant double long | 10 | 3.4*10-4932 à 3.4*104932 |
Avant de vous expliquer plus en détail ce que signifie “signé” et “non signé”, de vous parler du type float et char, je vais vous parler un peu de l’alignement mémoire car là aussi il est question de place…
Alignement mémoire
En mémoire on pourrait imaginer que toutes les variables se donnent la main et sont heureuses ensemble comme présenté dans ce fragment de mémoire :

Mais pour des raisons pratiques très bien expliquées dans cet article de dieu Wikipedia, la réalité est généralement moins glamour et le stockage en mémoire des variables dépend de l’ordre dans lequel elles ont été déclarées :
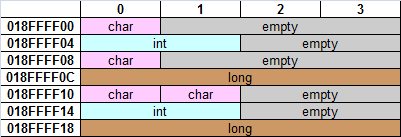
Vous pouvez aussi lire l’exemple 27 de cet article qui présente également tout ça très bien : www.viva64.com/en/a/0065/
Signed et Unsigned
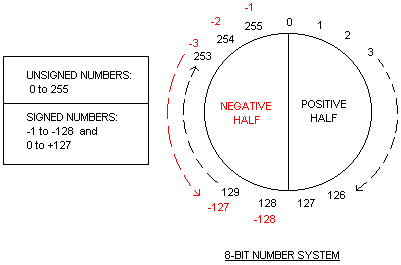
L’expression signed et unsigned permet de désigner une méthode de lecture de ces espaces plus ou moins grands. On dit qu’un nombre est signé lorsque le bit de poids fort (le bit le plus à gauche dans une représentation classique) n’est pas utilisé comme unité de valeur mais comme indicateur du signe, positif (valeur 0) ou négatif (valeur 1), mais voyez plutôt :
Programme de démonstration :
#include <stdio.h> main() { // num1 signed : 0 // unsigned 0 int n1=0b00000000000000000000000000000000; printf("num1 signed : %d // unsigned %u\n",n1, n1); // num2 signed : 1 // unsigned 1 int n2=0b00000000000000000000000000000001; printf("num2 signed : %d // unsigned %u\n",n2, n2); // num3 signed : -2147483648 // unsigned 2147483648 int n3=0b10000000000000000000000000000000; printf("num3 signed : %d // unsigned %u\n",n3, n3); // num4 signed : -2147483647 // unsigned 2147483649 int n4=0b10000000000000000000000000000001; printf("num4 signed : %d // unsigned %u\n",n4, n4); // num5 signed : -1 // unsigned 2147483649 int n5=0b11111111111111111111111111111111; printf("num5 signed : %d // unsigned %u\n",n5, n5); }
Ainsi un octet, lorsqu’il est non signé peut prendre comme valeur de 0 (en binaire 00000000) à 255 (en binaire 1111 1111). Et lorsqu’il est signé, de -127 (en binaire 1000 0000) à 127 (en binaire 0111 1111) en passant par zéro (en binaire 0000 0000).
Le type float
Le type float permet de travailler avec les nombres à virgule. Leur stockage en mémoire est relativement complexe et mérite un article à lui seul. Je vous conseille de jeter un œil à celui-ci :
http://blog.netinfluence.com/2009/09/24/comprendre-les-nombres-a-virgule-flottante/
Le type char
Le type char permet de stocker en mémoire un caractère, c’est à dire une lettre ou un chiffre (Vous voyez, je vous avais bien dit que ma remarque serait utile ! ;-)).
Un char occupe un octet en mémoire. Un octet comme nous l’avons vu est avant tout un nombre. Heureusement Robert Bemer a eu la brillante idée de formaliser une table de relation entre nombres et caractères. Ce code est nommé code ASCII (American Standard Code for Information Interchange).
Par exemple d’après ce standard, la lettre X équivaut au nombre 88 et que le chiffre 8 équivaut au nombre 56.
Illustration par le C :
#include <stdio.h> main() { // Impression du caractère X char caractere1=88; printf("%c\n",caractere1); char caractere2='X'; printf("%c\n",caractere2); // Impression du caractère 8 char caractere3=56; printf("%c\n",caractere3); char caractere4='8'; printf("%c\n",caractere4); // Ci-dessous, une confusion commune entre une chaîne de caractères constituée de chiffres et un nombre '88' != 88... // *Attention* Ce code génère des warning à la compilation ! char caractere5='88'; printf("%c\n",caractere5); }
Est-il nécessaire de préciser que c’est véritablement sur ce type que la confusion est la plus fréquente et la plus fatale ? Oserais-je rappeler que dans le langage C et dans bien d’autres, les guillemets simples ou doubles indiquent une chaîne de caractère ? Une erreur de syntaxe au niveau du code et l’information utilisée sera complètement différente de celle voulue. Il en va de même si le choix du format de sortie a été mal choisi…
Vous voilà donc vernis !








